Úvod
Vše započalo snahou AMD o využití GPU jako speciálního koprocesoru, čemuž předcházela r. 2002 architektura Hammer, první architektura X86, která nabídla HyperTransport, na jehož druhém konci nemusí být vždy jenom severní most, jak jsme byli zvyklí u FSB, ale může tam být další procesor, či koprocesor.
.
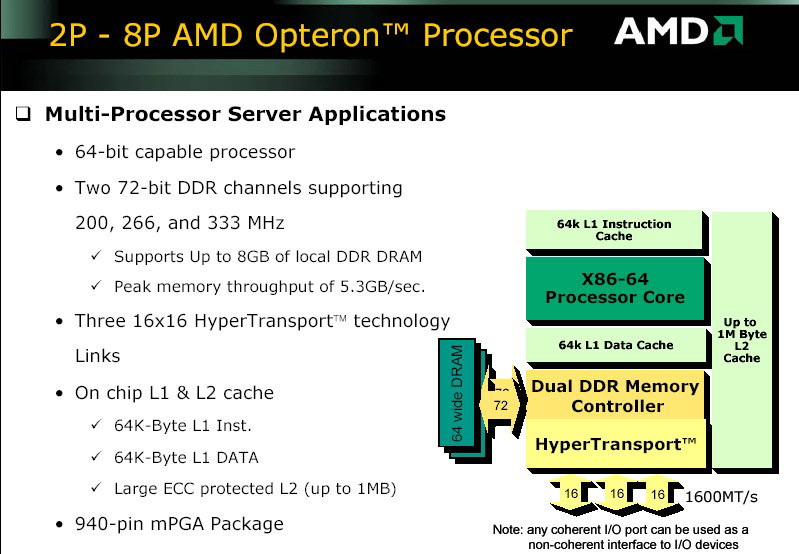
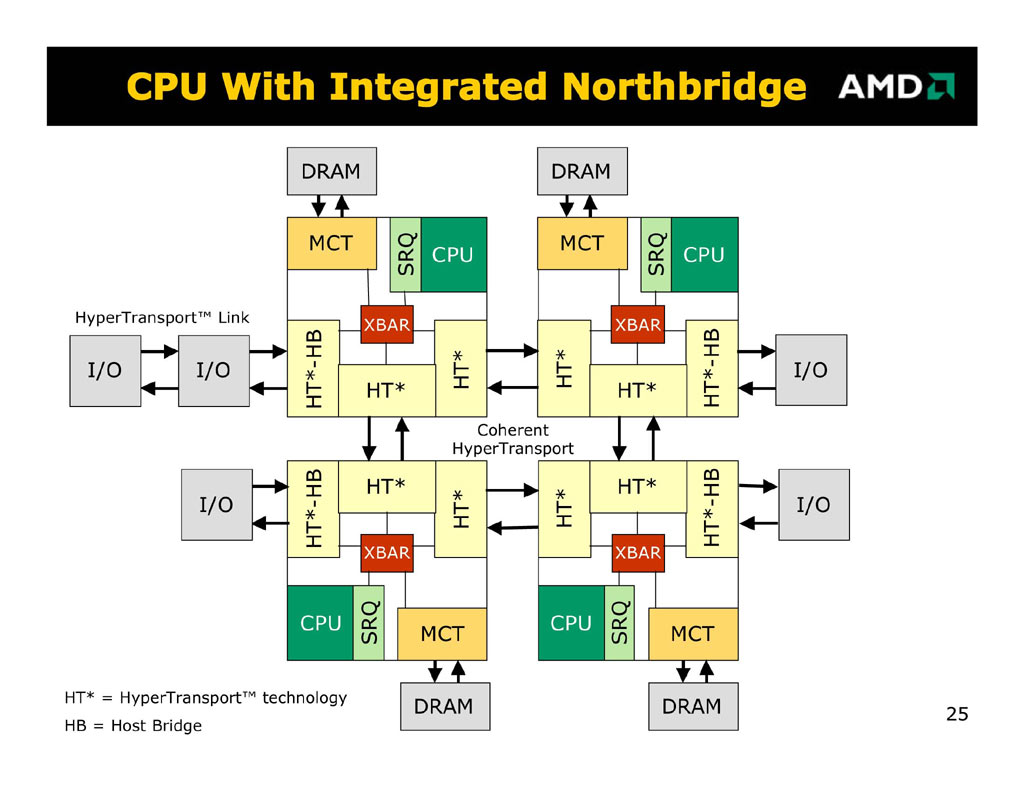
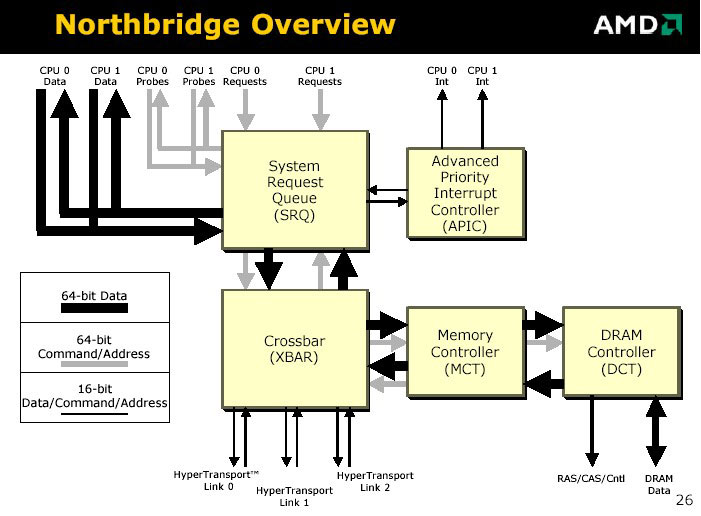
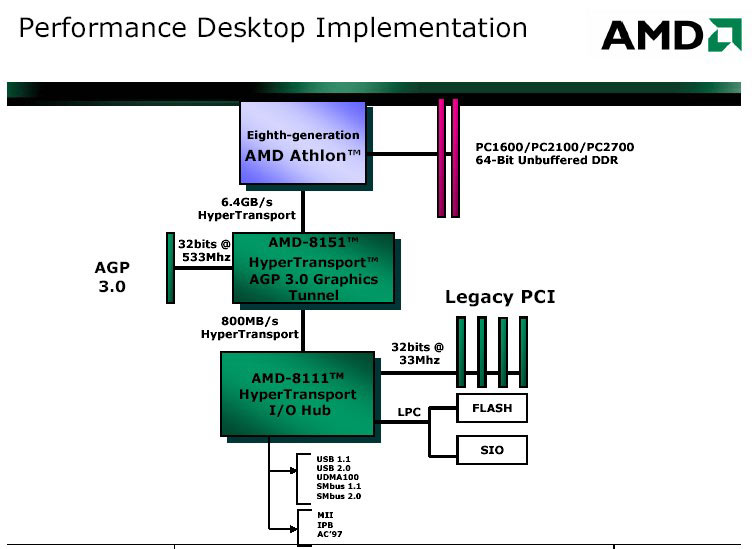
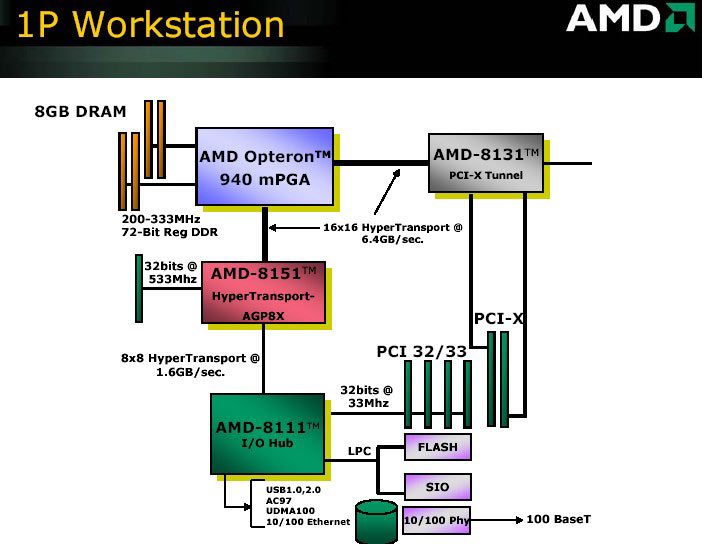
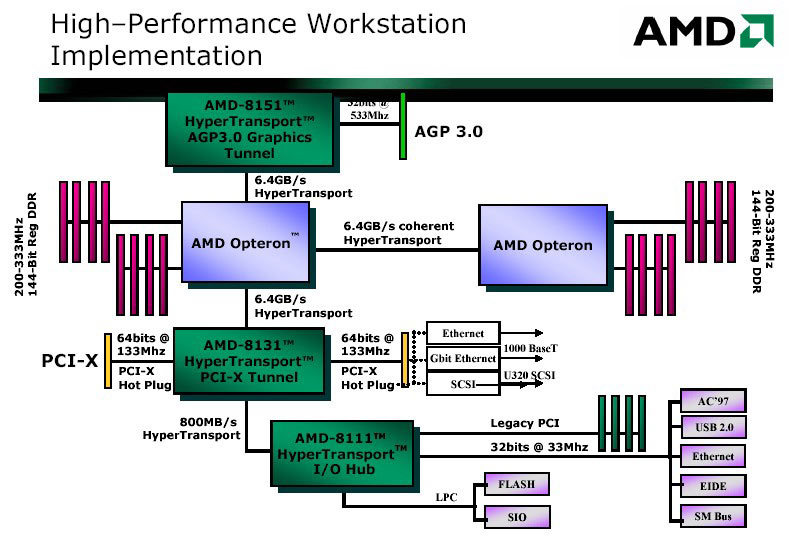
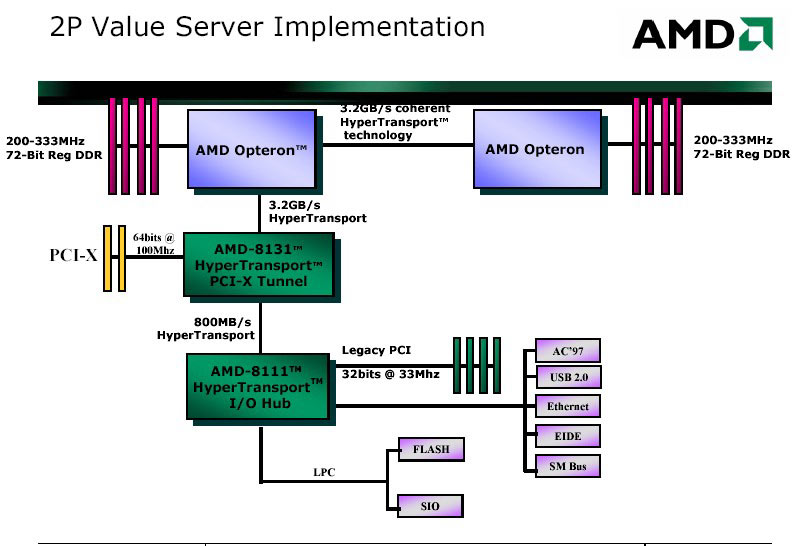
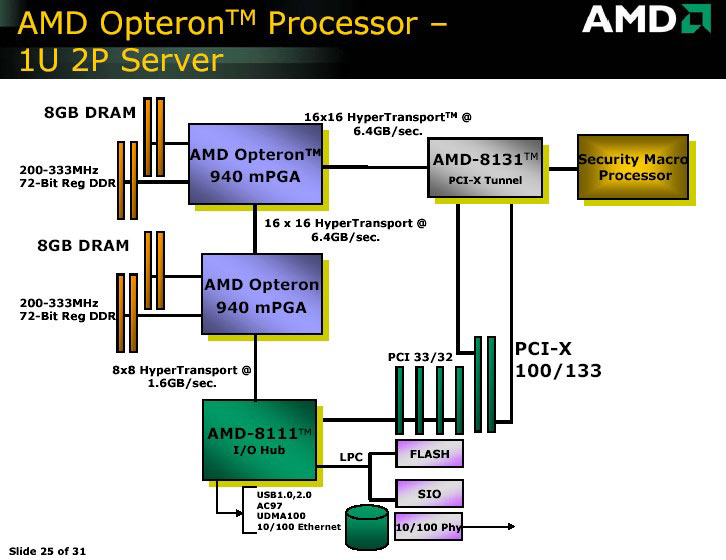
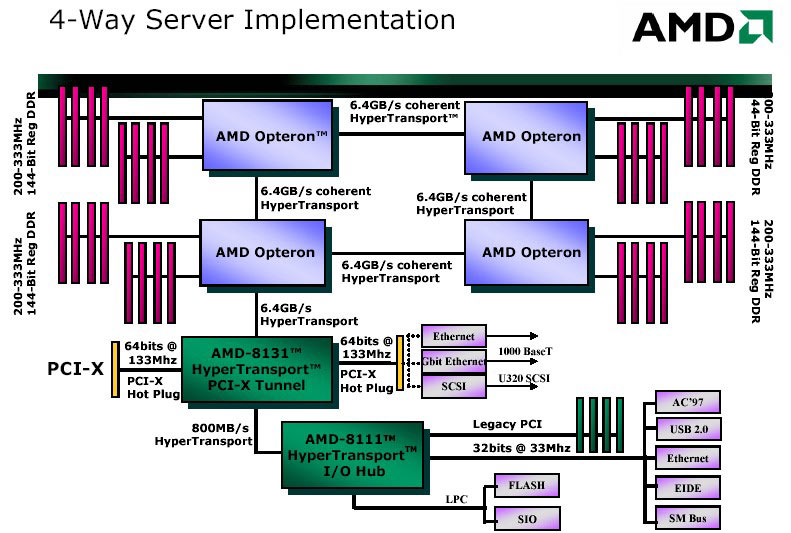
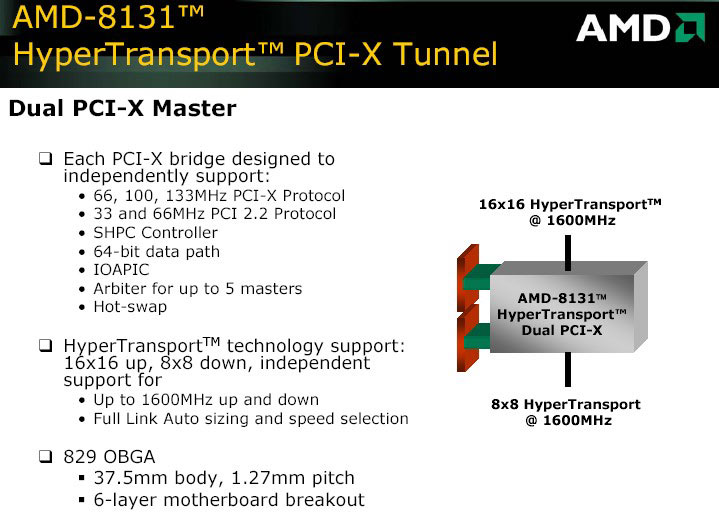

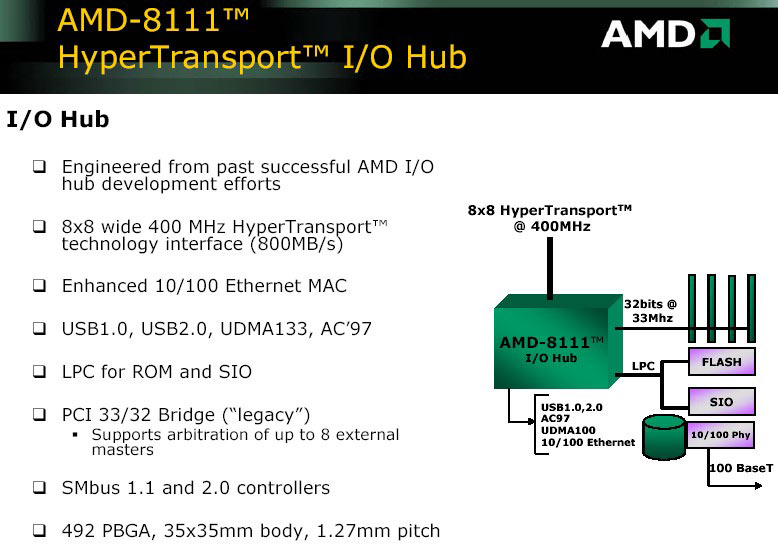
HyperTransport
HyperTransport výrazně změnil pohled na architekturu počítačů, dovolil rychlý přistup na úrovni procesoru, poprvé mohl procesor zaměstnat koprocesor, jehož výkon může být vetší než samotného procesoru.
Velmi pěkným řešením takové spolupráce procesoru a koprocesoru je Superpočítač "RoadRunner, the U.S. Department of Energy’s Los Alamos National Laboratory" 6.912 pouze dvou-jádrových AMD Opteronů, zaměstnává 12.960 speciálních IBM Cell eDP akcelerátorů.
Ale nespěchejme a poohlédněme se po celé historii, jak se vše vlastně krok za krokem vyvíjelo.
.
AMD oznamuje platformu Torrenza
Vzniká otázka, zda máme přídavné koprocesory zpátky, stejně jak tomu bylo u procesorů 486SX, 386 a starších, které mohly být dovybaveny matematickým koprocesorem.
Do procesorových patic se začínají vyrábět první koprocesory, které komunikují pomocí HyperTransportu, viz 96-jádrový procesor na frekvenci pouhých 250MHz, ClearSpeed CSX600, spotřeba 10W, výkon v plovoucí čárce 25GFlop/s (pětinásobek tehdejších procesorů).
V případě použití dvou koprocesorů se již získával úctihodný výkon, pomalu se začíná mluvit o HyperTransportu 3.0 a HTX konektorech.
.
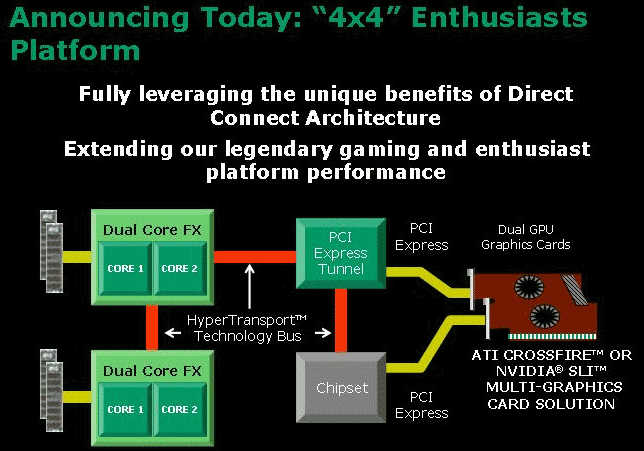
AMD oznamuje platformu AMD 4x4
Více méně pokračování Torrenzy pro dvou-procesorové sestavy, 4x4 právě proto, že ke slovu přichází dva dvou-jádrové procesory a dvě dvou-jádrové grafické karty.
Konkurence se vysmívá, ale Nvidia se hned přidává a Intel pro AMD Torrenzu "špatně spí?"
.
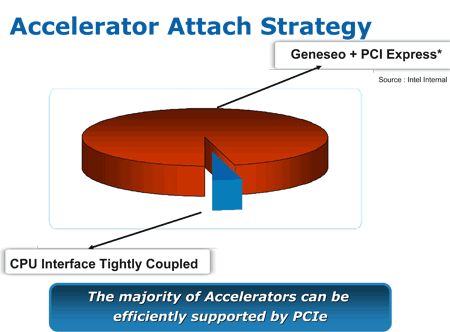
Na IDF Fall 2006 Intel ohlašuje Intel Geneseo
Intel Geneseo má být odpovědí na AMD Torrenzu, pokus dobrý, ale celá komunikace je závislá na FSB a dále sběrnici PCI-e, Intel Geneseo se baví s koprocesorem na úrovni severního mostu přes PCI-e, tuto možnost má však AMD taky, naopak Intel nemá možnost komunikovat na úrovni vlasního jádra.
.

AMD kupuje společnost ATI
Koupí společnosti ATI, za přehnaných 5,4mld USD získalo AMD přístup ke grafickým technologiím a může dále rozvíjet svůj odklon od klasické koncepce X86 procesorů.
.

AMD zpochybňuje vývoj mnoho-jádrových procesorů
Vedoucí technolog AMD p. Phil Hester, vyjádřil pochyby k momentálnímu vývoji procesorů, ve kterých jsou využívána zatím dvě nebo čtyři stejná jádra. Naznačil, že se AMD odkloní od tohoto směru a zaměří se více na APU (Accelerated Processing Units).
.
Myšlenka podobná s použitím integrovaného řadiče pamětí, AMD chce využít technologie ATI na cestě k heterogenním více-jádrovým procesorům. Již se běžně mluví o technologii AMD Fusion což má být zakončení postupného přechodu od AMD Torrenzy.
AMD Fusion znamená využití GPU jako APU přímo na úrovni jádra a cesta k řádu PFlop/s se zdá být otevřená. AMD v této oblasti vytvořila svou otevřenou platformu a Stream Computing.
SRC oznamuje podporu pro AMD Torrenzu
Vedení rekonfigurací systémů a zpracování dat u společnosti SRC Computers v Coloradu oficiálně oznámilo, že bylo zahájeno testování AMD Torrenzy s HP ProLiant DL385 servery.
.
Prezident CEO SRC Jon Huppenthal říká, že vysoká šířka pásma vzájemného spojení a vyšší programovací jazyk programovacího prostředí pro platformu AMD Torrenza dovoluje vyvinout aplikace pro SRC systémy se zachváním kompatibility programového vybavení bez ohledu na typ mikroprocesoru. AMD Opteron se svým HyperTransportem je otevřen přímému spojení již pět let.
.
Vznikla možnost navýšení základního výkonu procesoru až 100x pomocí jednoúčelového koprocesoru atd.
GPU-Tech, GPU počítání
Vývoj procesorů došel ke svému rozcestníku jejímž nositeli byly architektury NetBurst a Hammer.
- 1. NetBurst stavěl na vysokých frekvencích
- 2. Hammer naopak na vyšším IPC a integrovaném řadiči paměti.
- 3. V téže době pokročil vývoj GPU k ještě větší datové šířce a k ještě větší paralelizaci výpočtů a výkon se začína velmi rychle vzdalovat X86 procesorům.
.
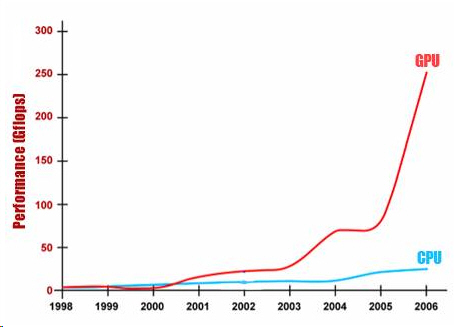
Na tomto základě vznikla zatím malá firmička GPU-Tech zabývající se počítáním pomocí GPU. Podstatou rychlejšího počítání pomocí GPU je využiti Pixel Shaderů namísto pipe line, jak jsme zvyklí u CPU. Pixel Shaders je program v jazyce symbolických adres, jehož délka může být až 65 tis. instrukcí na rozdíl od pipel line, která bývá dlouhá v řádu jednotek či desítek.
Tímto může GPU pracovat řádově na tisících vláknech současně. Použitelné instrukce jsou goniometrické funkce, logaritmy, odmocniny, mocniny, práce s maticemi, vektory a další. Rovněž je možno tvořit podmínky, větvení, smyčky, apod. Další výhodou je značná šířka sběrnice a tedy již 320 stream procesorů. Takto vypočítané části, či proměnné, pak CPU slouží jako data pro jeho další výpočty. Bylo jen otázkou času, kdy se počítání pomocí GPU stane součástí našeho života.
EXOCHI Pro od Intelu
Intel na sebe nenechal dlouho čekat a ohlásil "EXOCHI Pro" svůj systém GPU počítání. AMD se snaží tuto technologii uvést v život pod názvem Torrenza či Fusion, kde jejich odlišnost je více méně jen ve stupni integraci grafického jádra do procesoru. Intel, který má rovněž do této problematiky co říci.
.
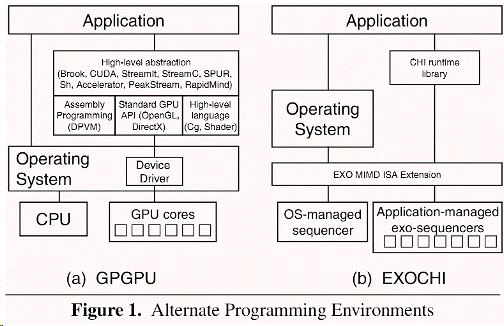
Za tímto účelem vytvořil svou architekturu a programovací prostředí EXOCHI Pro a různorodý více-jádrový a více-vláknový systém. Intel zde přiznává, že u příští generace procesorů je integrace speciálních akcelerátorů - jako je dnes i GPU - k dosažení lepšího výkonu a výkonové efektivity již naprosto nevyhnutelná, atd.
DRC- RPU110-L200 - koprocesor pro AMD
.

Vedení prodeje dynamických rekonfigurací koprocesorových jednotek DRC Computer Corporation, počítačové společnosti založené v roce 2004, která má sídlo v Sunnyvale, Californii, oznámilo použitelnost jejich RPU110-L200 koprocesoru.
.

Senior viceprezident (na starost má strategie společnosti a rozvoj obchodu výkonných počítačů), Jan Silverman, říká, že v některých aplikacích může dojít k navýšení výkonu až 100x, atd.
NVIDIA nevytvoří CPU, přesto chce mít nejvýkonnější PC
.

Takto se nechal slyšet Huangrenxun na schůzce investorů NVIDIA, kde několikrát zopakoval, že nepotřebujeme třetího světového výrobce CPU. Huangrenxun seznámil investory s pohledem na GPU pole a jeho další možnosti.
.
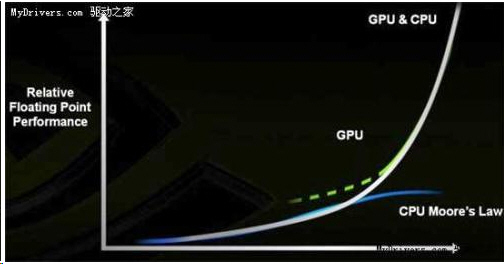
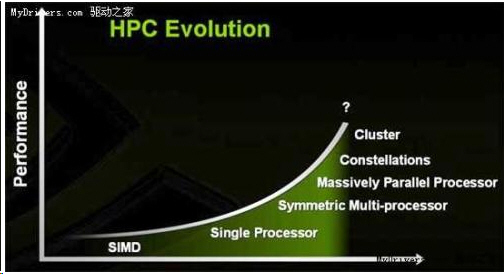
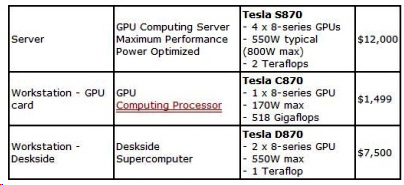
Na procesorovém trhu je dostatek výrobců v čele s Intelem, dále AMD, VIA, Transmenta a IBM. NVIDIA se zde nehodlá angažovat, spíše CPU dává podpůrnou roli pro jejich vysoce účinný počítač „TESLA“.
Vysoká účinnost byla dosažena navzdory použití běžné počítačové platformy, je nutné se spoléhat na CPU, složitost GPU je srovnatelná se složitosti CPU, vývoj je rovněž značně složitý a obtížný, znovu pak zopakoval, že NVIDIA nemíří k CPU.
AMD Fusion již 2009?
V technické analýze AMD odhalilo plány na roky 2007-2009, kde na poli počítačů plánuje AMD rozvoj zahrnující procesory, čipovou sadu, grafickou kartu a paměti včetně mnoha dalších aspektů. AMD plánovalo během tří let vypustit celkem šest platforem, z toho tři nejvyšší třídy a tři pro hlavní proud. Jednotlivé třídy měly vypadat následovně.
.
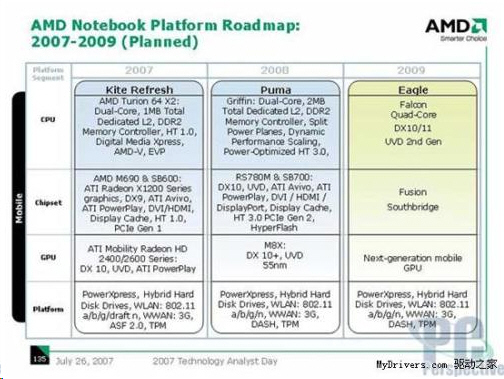
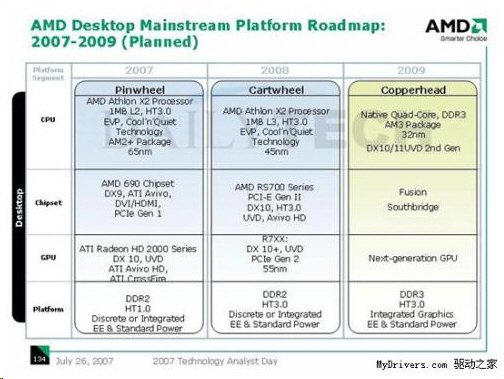
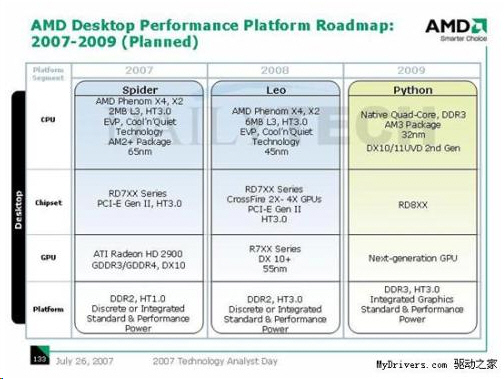
AMD normalizuje hardwarovou škálovatelnost softwaru?
Takto složitě lze popsat dokument vydaný společností AMD. V podstatě jde o snahu zavést jistý řád a znormalizovat dělbu práce mezi jednotlivými procesory u více procesorových systémů a desek.
Mluví se o dvou technologiích - LWP (Light-Weight Profiling) a HESP (hardware scalable software parallelism). Obě jsou umístěné v aplikačním softwarovém rutinním prostředí s Javou a .NET Frameworkem. Prostředí zajišťuje plánování a kódování v dynamickém i reálném čase k zajištění optimalizovaného běhu zpracovávaného kódu na více procesorech současně.
.
Jinými slovy, tento software zajišťuje dělbu práce mezi jednotlivé procesory. Měl by být aplikován při vývoji jak software, tak i hardware. Údajně byl k tomuto projektu přizván i Intel, ale ten se prostřednictvím svého mluvčího nechal slyšet, že oficiální přizvání k projektu od AMD nepřijímá.
AMD K10 přináší 128bitový SSE5 instrukční soubor
S příchodem architektury AMD K10 se v procesorech objevily i další 128bitové instrukce. Značná část těchto instrukcí bude zapotřebí až s nástupem architektury „Buldozer“.
.

SSE5 dávají vývojářům další možnosti dosažení maximalizace výkonu ve spotřebitelských aplikacích, výkonovém počítání, multimediálních a bezpečnostních aplikacích.
Zveřejněním specifikací 46 základních a dalších rozšiřujících SSE5 instrukcí, jejichž celkový počet by měl dosáhnout až 170, již dnes dává AMD více času pro adaptaci u výrobců a uživatelů softwaru.
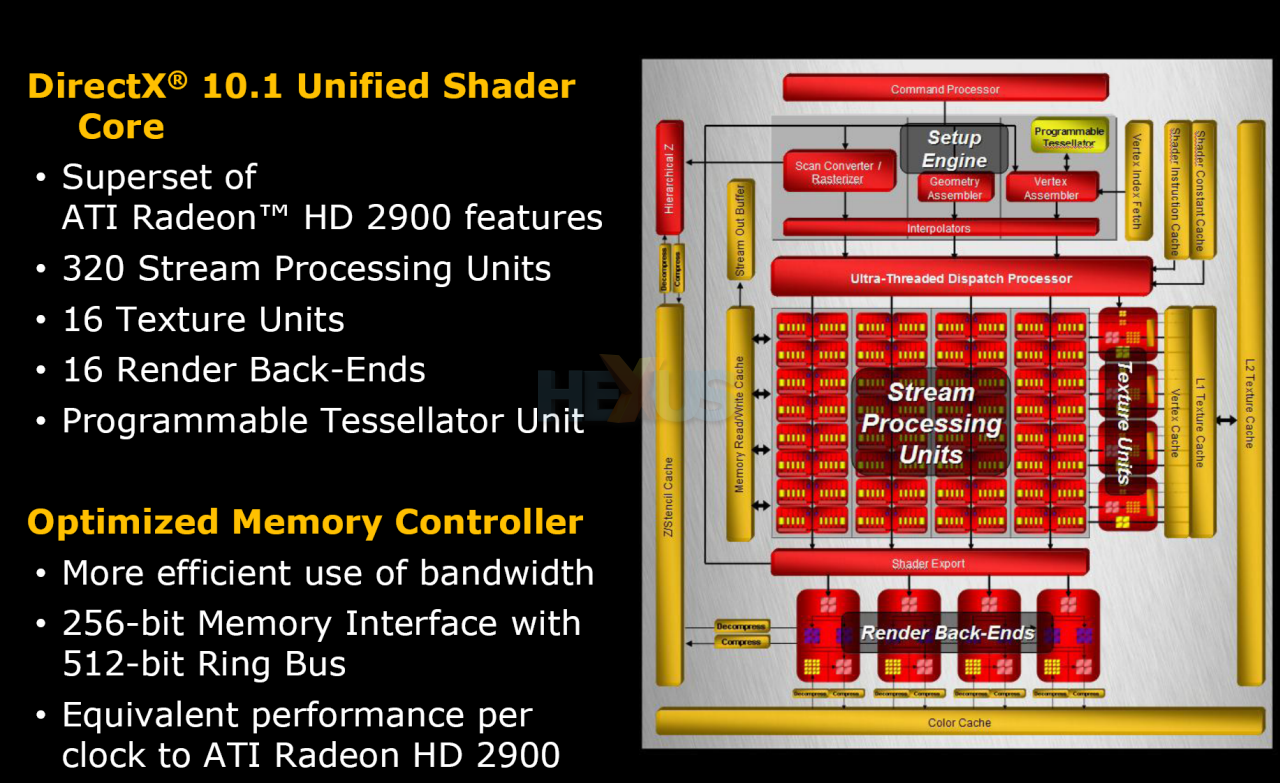
Podpora DirectX 10.1
AMD jako jediný HW výrobce s předstihem před samotným Microsoftem dal svým produktům podporu DX10.1, která je jakýmsi nakročením k DX11, tomuto účelu vytvořil i SSE5 a technologie LWP a HESP. Intel se nikterak aktivně neangažuje, Nvidia předpokládá vývoj k OpenCL 1.0 a DX11 spíše přes Nvidia CUDA, obejitím DX10.1.
.
Závěr
Mnohé se splnilo a mnohé na své splnění ještě čeká, mimo uvedené plány vznikla specifikace OpenCL 1.0, kde se Nvidia všemožně snaží přiklánět specifikace k technologiím Nvidia CUDA, když ne specifikace pak alespoň mínění veřejnosti, že tomu tak je. Občas vznikne další nejvýkonnější karta pro GPU počítání jako "FireStream™ 9270 nový GPU CPU král!" Intel si jde svou vlastní cestou a snaží se vytvořit své Intel Larrabee.
Vše se ubírá pomalu cestou sjednocení prostřednictvím OpenCL a DirectX 11, kde DirectX 11 se zaměřuje více na zpracování realtime 3D grafiky a OpenCL 1.0 na akceleraci výpočtů pomocí GPU. Mnohé jsem neuvedl, nelze však uvést úplný výčet a na nikoho nezapomenout.
Faktem zůstává, že většina iniciativy pocházela od společnosti AMD, ostatním zainteresovaným však nelze upřít jejich podíl na postupné tvorbě celé koncepce. Společnost AMD se od počátku snažila nabízet alternativy a vést koncepci směrem ke zcela otevřené. Společnosti Nvidia se nedá upřít její podíl s Nvidia CUDA, ale naopak její postoj s "uzurpováním" si zásluh na GPU-CPU počítání je spíše brzdou celého vývoje, dochází spíše k tříštění sil a tvorbě protichůdných směrů.
Diskuse
Zdroj: TGDaily, BusinessWire, AMD, GPU-Tech, iXBT ,DRC, DRC-RPU110 (pdf), Geek, AMD, Presence-pc, Mydrivers, Mydrivers, AMD (pdf), MyDrivers, AMD (pdf)